
Overview (SQL Syntax)
Why SQL?
Structured Query Language (SQL) is a standard declarative language used to describe the desired result of data. Unlike other procedural languages (like Python, Java, Rust, etc.) that require the user to specify the exact steps the computer should take, SQL is declarative, meaning users describe the final output, and allow the SQL parser program to construct the exact steps automatically at runtime. This dramatically simplifies the work of generating and optimizing complex data manipulations down to a very simple and intuitive set of commands that almost anyone can learn.
Given SQL’s long success, it is often said “the business world runs on SQL.” While there are many extensions and variations of SQL, the American National Standards Institute (ANSI) has defined what SQL should look like, and data systems that adhere to that standard are referred to as ANSI-Compliant SQL. This consistency of SQL has allowed an entire industry of analytic systems and tools to interoperate with such efficiency that it is still the standard today.
Space and Time is a data warehouse, and as such operates on ANSI-compliant SQL. There are several Space and Time extensions that allow us to better operate as a decentralized Web3-native data system.
SQL Syntax – The Basics
The SQL syntax has matured over the last 40 years to be far more robust and comprehensive than could be reasonably documented here. If you would like to learn more about SQL in general, below are several good online courses to educate on SQL basics:
- Udemy - The Complete SQL Bootcamp
- Coursera / UCDavis - SQL for Data Science
- Educative - An Introductory Guide to SQL
- ZeroToMastery - Complete SQL + Databases Bootcamp: Zero to Mastery
- FutureLearn - Introduction to Databases and SQL
TL;DR
If you’re looking for an over-simplified SQL primer, there are 5 parts to a basic SQL statement:
SELECT– list of columns to return, or use asterisk (*) to indicate all columnsFROM– one or more tables, that contain the dataWHERE– filters to reduce data returned from tablesGROUP BY– in aggregations, specifies which columns drive the grouping, while all other columns must be wrapped in an aggregate function like SUM()ORDER BY– specifies the order in which data is returned
For example, the SQL below would return the aggregate count of transactions per day from the Ethereum blockchain that exist within a range of 1 million Blocks:
SELECT
CAST(TIME_STAMP as DATE) as BlockDate
,SUM(TRANSACTION_COUNT) as TxnCount
FROM ETHEREUM.BLOCKS
WHERE BLOCK_NUMBER between 14e6 and 15e6
GROUP BY BlockDate
ORDER BY BlockDate;Once users understand that CAST() turns one data type into another (in this case, a full timestamp to just the date) and the scientific notation 14e6 = 14 million, then the above SQL becomes very readable.
If you are running SQL queries on your own tables and looking to reduce latency or increase data power, there are SQL hints that you might consider.
SQL Hints - Manually Selecting the DB Engine
This is an Advanced SettingAll things being equal, you should allow the network to select the best processing engine. Only use the settings below if you are having issues with transactional performance.
Space and Time is a "Hybrid Transactional/Analytic Process" (HTAP) data warehouse, meaning there are two optimized engines embedded in the product, one for low-latency OLTP transactions, and another for big data OLAP analytics:
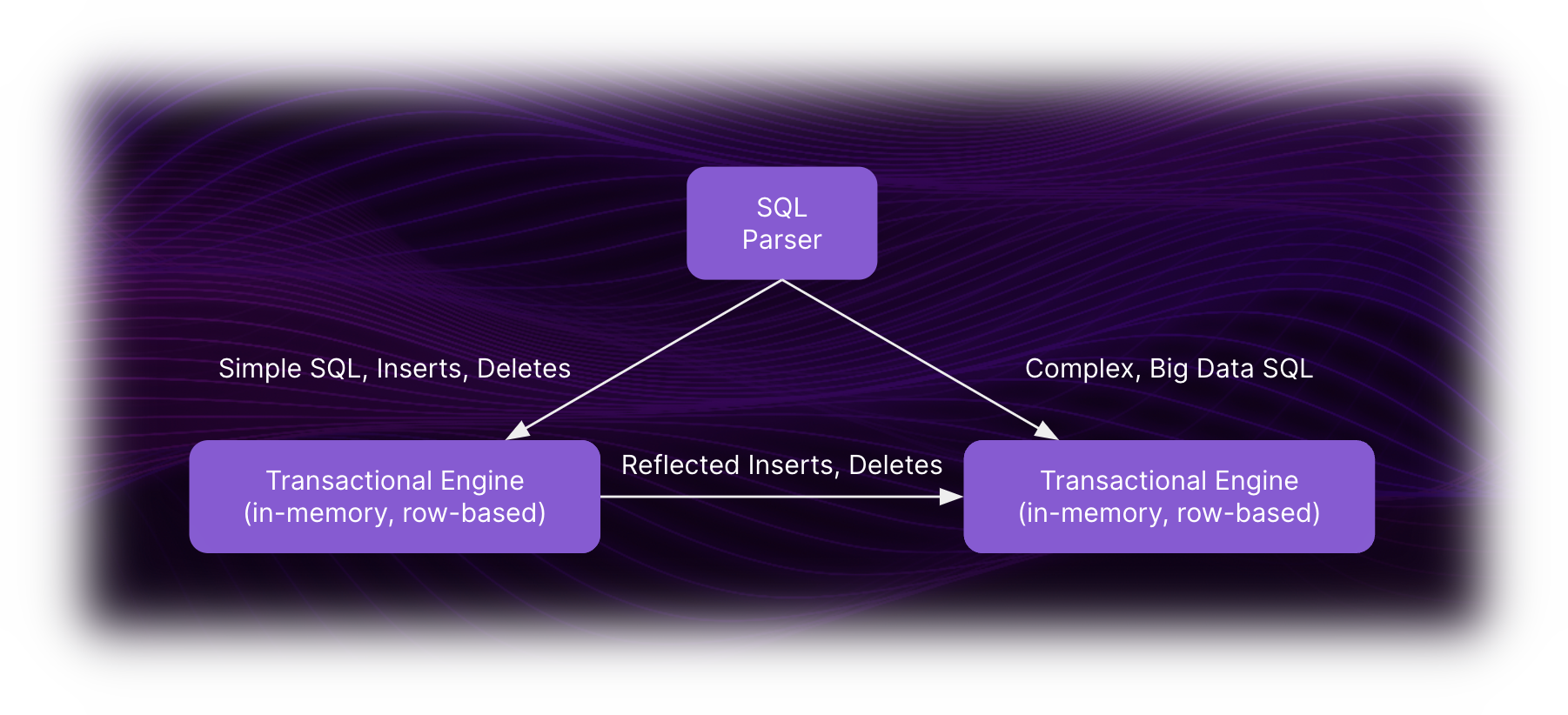
The SQL Parser will automatically make the best choice based on the complexity and type of query. However, there are occasionally use-cases where you may want to force your query to one particular engine. For example, inserting a new record, followed immediately by a big-data query - where it's possible the big data query is started before the insert has been synced, and doesn't show up as expected.
There are two SQL hints that force the query to a particular engine: /*! USE ROWS */ will force the query to the transactional engine, and /*! USE COLS */ will force the query to the big data engine. These hints are placed immediately behind the SELECT statement. For example:
Select /*! USE ROWS */ SYMBOL, STOCK_DATE, STOCK_HIGH
from SXTDEMO.STOCKS
where cast(STOCK_DATE as date) = '2023-04-21' and Symbol = 'MSFT'Because this is a simple query returning one row, the network is likely to select the transactional engine automatically. Forcing an OLTP query to the OLAP engine with /*! USE COLS */ returns the same data, but increases the runtime from 100ms to 1400ms - because it's not the right engine for the query!
Also be aware - the transactional engine doesn't have the full set of data as the big data engine. For example, while blockchain data is highly optimized, it exists only on the big data engine - forcing an OLAP query on the Ethereum history table to use the OLTP engine with /*! USE ROWS */will return no rows.
There is much more to SQL than the above 5 components, but that additional complexity is built on this foundation, which makes it a good starting point.
Best Practices for General SQL
These best practices will apply to almost all data warehouse systems, and are true for Space and Time as well:
Filter early – for more complex queries, apply WHERE statements as early as possible. For example, if youre joining two sub-selects, you can often apply the WHERE statement once in the outer statement, or redundantly twice in each sub-select. The advantage of doing it twice is reducing the number of rows for each data set before the join, which can change a 5 second runtime into a 500ms runtime.
LIMIT 10 – during initial discover, it is not uncommon for analysts to SELECT * FROM Schema.Table_Name to start exploring data type, format, and sample data. That said, an unconstrained SELECT can generate a fair amount of compute on the system as it attempts to return the entire table (potentially millions of rows) to the client application. Even if the database compute is fast, the network latency moving large data will make the response feel slow. By adding LIMIT N to the end of the query, the database will only return the first N-number of records, then stop processing. For example, SELECT * FROM Schema.Table_Name LIMIT 10 will return the first 10 rows only. Do note: LIMIT is not the same as SAMPLE. LIMIT will simply return the first 10 rows the database can find, often (but not always) sequentially stored on disk, making it not suitable for a random sample.
Know the Key – when working with very large data, you will get better performance when filtering or joining on a table’s Key Column, as it aligns with how the data is physically stored. For example, the ETHEREUM.BLOCKS table’s key is Block_Number (primary key, meaning it is unique). Any joins or filters on Block_Number will return faster than the similarly unique Block_Hash column. A table’s key can be found using the Resource Discovery API, or in the JDBC driver and exposed through most modern SQL Editors.
Snake_Case – the typical convention for SQL names is Snake_Case, aka using underscores to separate words, for example, Block_Number or Gas_Fee. Like any convention, there is no technical advantage other than consistency with other SQL developers.
SQL Syntax – Space and Time Specifics
Space and Time is an ANSI-Compliant database, meaning normal SQL will work as expected. That said, like any unique data system, there are some unique characteristics that are worth noting. The subpages in this section list the unique data types and reserved words for Space and Time.
Pricing
When you use Space and Time, all you pay for is compute. Storage, indexed blockchain data, OpenAI dashboards, OLTP + OLAP queries in your cluster, Proof of SQL cryptography, and more are always included.
We offer several different pricing options to fit your needs and your use case. Visit this page to learn more.